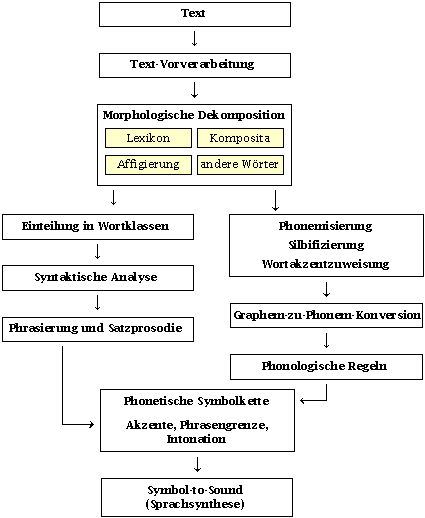
Wie ist ein Sprachsynthesesystem aufgebaut?
Jürgen Trouvain · Universität des Saarlandes
Fachbereich 8.7, Phonetik · 66041 Saarbrücken
e-Mail:
trouvain@coli.uni-sb.de
Anmerkung des Herausgebers
Da im HTML-Format, welches für das World-Wide-Web benutzt wird, zur Zeit
noch keine phonetischen Symbole verfügbar sind, sind die entsprechenden
Stellen in dieser Online-Version nicht korrekt wiedergegeben. Es wird daher
hierzu auf den gedruckten Band verwiesen; allerdings sind die entsprechenden
Stellen für phonetisch »Vorbelastete« vom Zusammenhang her dennoch
erschließbar.
Der nachfolgende Beitrag soll den prinzipiellen Aufbau eines
Systems erläutern, das geschriebene Texte in gesprochene Sprache
umwandelt. Es gibt andere, mehr mit statistischen Methoden arbeitende
Ansätze; die linguistisch basierten Systeme arbeiten jedoch vorwiegend
mit einer Architektur, die der vorgestellten ähnelt.
Beispieltext
Die einzelnen Verarbeitungsschritte, die
durchgeführt werden, bis das akustische Sprachsignal erzeugt worden
ist, sollen am folgenden Beispiel gezeigt werden: Vom
24. bis zum 28. Mai 1995 finden an der Universität des Saarlandes die
beiden Studententagungen StuTS & TaCoS statt.
Textvorverarbeitung
Unter den Schritt der Textvorverarbeitung
(text preprocessing) fällt zum Beispiel die Umwandlung von Ziffern in
eine ausbuchstabierte Vollform; außerdem wird von dieser Stufe
erkannt, daß es sich bei »1995« um eine Jahreszahl
handelt. Schließlich werden Sonderzeichen in ausbuchstabierte
Vollformen umgesetzt; im Beispiel betrifft dies das »&« und die Punkte
nach den Ziffern. Vom vierundzwanzigsten bis zum
achtundzwanzigsten Mai neunzehnhundertfünfundneunzig finden an der
Universität des Saarlandes die beiden Studententagungen StuTS und
TaCoS statt.
Morphologische Dekomposition:
Morphemlexikon
Die einzelnen Wörter des Textes werden aufgrund
eines Morphemlexikons analysiert. Dieses Lexikon enthält die
wichtigsten Morpheme und die für die Sprachsynthese relevanten
Informationen. Bei Lexemen sind dies Angaben zur Wortbildung, zur
phonemischen Form und zur Setzung des Wortakzents; zu Affixen werden
die phonemische Form, der Wortakzent und die Silbengrenze
gespeichert. So könnte ein Lexikon für unser Beispiel einen Eintrag
für das Simplex »Universität« enthalten, wobei dort die Information zu
finden wäre, daß bei diesem Wort die letzte Silbe betont wird.
Aufgrund der Einträge im Morphemlexikon können zudem Komposita
analysiert werden: »Studententagungen« wird in Student-en-tag-ung-en
zerlegt. Dagegen wird ein Sprachsynthesesystem wohl nichts mit den
Wörtern »StuTS« und »TaCoS« anfangen können; diese unbekannten Wörter
werden daher gesondert behandelt.
Morphologische Dekomposition:
Unbekannte Wörter
Wörter, die von der Morphologie-Komponente
nicht verarbeitet werden können, dürfen nicht einfach übersprungen
werden, da sonst der Text unvollständig vorgelesen würde. Daher
sollten unbekannte Wörter soweit als möglich interpretiert werden:
StuTS und TaCoS weisen wegen ihrer unregelmäßigen, aber für
Abkürzungen typischen graphemischen Form auf eine Abkürzung hin, die
als ein normal auszusprechendes Wort zu behandeln wäre (also Stuts,
Tacos); ebenfalls denkbar wäre ein Buchstabiermodus. Es ist ein
erstaunlich schwieriges Problem, zu bestimmen, ob eine Abkürzung als
Wort ausgesprochen oder buchstabiert wird: »USA« wird im Deutschen
buchstabiert, »UNO« als Wort gesprochen.
Morphologische Dekomposition: Silbengrenzen
Nachdem die Wörter des
auszusprechenden Textes phonemisiert wurden, sind als nächstes die
Silbengrenzen zu bestimmen. Dazu braucht man zum einen morphologische
Angaben, zum anderen werden eigene Silbifizierungsregeln benötigt. Die
Silbengrenze kann mit der Morphemgrenze übereinstimmen, muß es jedoch
nicht zwangsläufig. Beispielsweise trifft beim Wort »beerdigen« die
erste Silbengrenze (be-erdigen) mit einer Morphemgrenze zusammen, die
restlichen Silbengrenzen (beer-di-gen) jedoch nicht.
Morphologische Dekomposition: Wortakzente
Die Wortakzente
sind für die Morpheme bereits im Lexikon angegeben; für neue Wörter
(zum Beispiel Komposita) müssen Regeln angewendet werden, um die
Wortakzente zu bestimmen. Das Wort »Studententagungen« besteht aus
den beiden Morphemgruppen »Studenten« und »tagungen«, die sich jeweils
um ein Stammorphem bilden. Eine entsprechende Regel für Wortakzente
könnte festlegen, daß bei solchen Komposita der Wortakzent auf dem
ersten der beiden Teile stärker ist.
Graphem-zu-Phonem-Umwandlung
Gänzlich unbekannte Wörter, aber
auch Wörter mit unbekannten Morphemen, müssen mittels sogenannter
Graphem-zu-Phonem-Regeln phonemisiert werden. Je weniger im Lexikon
und bei der morphologischen Analyse zur Phonemisierung beigetragen
wird, desto besser muß die Umwandlung der orthographischen in die
phonemische Form in diesem Schritt verlaufen. Die Silbifizierung und
die Zuweisung des Wortakzents geschieht auch bei unbekannten Wörtern
nach den oben beschriebenen Regeln, sobald eine phonemische Form
bestimmt wurde. Nach dem Durchlaufen der besprochenen Schritte
könnte im fiktiven Beispielsystem der Text zu folgender Form
umgewandelt sein:
fçm-fir-Unt-tsvan-tsIgs-t´n-bIs-axt-Unt-tsvan-tsigst´n-maI-nçYn-tsen-hUn-d´rt-fYnf-Unt-nçYn-tsig-fIn-d´n-an-der-u-ni-vEr-zi-tEt-d´s-zar-lan-d´s-di-baI-d´n-StU-d´n-t´n-ta-gU-N´n-StUts-Unt-ta-kçs-Stat
Phonologische Regeln
Die nun erzeugte abstrakte phonemische
Ebene der Sprachlaute muß als nächstes zu einer realistischeren
phonetischen Ebene umgewandelt werden, die jene Lauteinheiten enthält,
die für die Sprachsignalerzeugung relevant sind. Beispielsweise
wird in /fir/ für das /r/ die vokalische Variante [a] eingesetzt;
diese Variante wird immer innerhalb einer Silbe nach Langvokalen
gewählt.
Das /g/ in /tsIgs/ wird entweder durch die
sog. Auslautverhärtung zu [k] oder wird zu [C]; diese Erscheinung
tritt immer dann auf, wenn einem stimmhaften Obstruenten /b, d, g, v,
z/ entweder ein stimmloser Laut (wie in /tsIgs/) oder eine
Silbengrenze (wie in /tsIg/) folgt.
Das /t/ in /StU/, in /Stat/
und in /StUts/wird ohne Aspiration realisiert, da ein /s/ oder /S/
vorhergeht; im Gegensatz zu /ta/ in TaCoS, das aspiriert ist [tH].
Nach dem Anwenden der phonologischen Regeln erhält man als Ergebnis
eine Kette phonetischer Symbole:
fçm-fia9-Unt-tsvan-tsIks-t´n-bIs-/axt-Unt-tsvan-tsiks-t´n-maI-nçYn-tsen-hUn-d´a9t-fYnf-Unt-nçYn-tsik-fIn-d´n-an-dea9-/u-ni-vEr-zi-tHEt-d´s-zar-lan-d´s-di-baI-d´n-StU-d´n-t´n-ta-gU-N´n-StUts-Unt-tHa-kçs-Stat
Syntaktische Analyse
Die syntaktische Analyse benötigt
Angaben aus der Morphologie, damit eine Struktur des Satzes gefunden
werden kann. Von Bedeutung sind hier unter anderem Informationen zur
Wortklasse oder zu Genus, Kasus und Numerus. Das Ergebnis des
Analyse unseres Beispielsatzes zeigen wir als Baumstruktur an, wie sie
intern dargestellt werden könnte:
(S
(VORFELD
(PP-AUFZAEHLUNG (PP (P-KLITISCH vom) (ORDINAL 24.))
(PP (P bis) (DATUM 28. Mai 1995))))
(FIN-V finden)
(MITTELFELD (PP (P an) (NP (DET der)
(N-BAR (N Universitaet)
(NP (DET des) (N-BAR (N Saarlandes)))))
(MITTELFELD (NP (DET die)
(N-BAR (N-BAR (ADJ beiden)
(N-BAR (N Studententagungen))))
(NP (KOORDINATION (N Stuts)
(KONJUNKTION und)
(N Tacos)))))))
)
(V-PRAEFIX statt)
)
Phrasierung und Satzprosodie
Aufgrund der Aufteilung des
Satzes in seine syntaktischen Bestandteile wird nun versucht, eine
Gliederung in prosodische Gruppen vorzunehmen. Solchen Einheiten von
Wörtern, die eine »Sinneinheit« bilden, kann daraufhin ein Akzent
zugeordnet werden; durch diese Stufe wird also entschieden, welche
Silben besonders hervorgehoben sein sollen. Hauptsächlich auf diesen
Akzenten spielt sich das intonatorische Geschehen ab, dessen Länge von
der Phrasengrenze abhängt und dessen Art vom Satzmodus bestimmt
wird. Hierbei kommt auch die Bestimmung des Wortakzentes zum Einsatz.
vom 24. | bis zum 28. Mai 1995 || finden | an der Universität | des Saarlandes || die beiden Studententagungen | StuTS | & TaCoS statt.
Akzent, Intonationskontur und Phrasengrenze
Bevor das akustische Signal generiert werden kann, müssen noch
Informationen zur Stärke des Akzents, die Intonationskontur sowie die
Phrasengrenzen der segmentellen bzw. silbifizierten Kette zugeordnet
werden. All dies hat Auswirkungen auf phonetische Parameter wie Dauer,
Intensität, spektrale Eigenschaften (Klangqualität) und
Grundfrequenzänderung.
Erzeugen des Sprachsignals: Formantsynthese
Als letzter
Schritt muß die phonetische Form (inkl. aller zusätzlichen Parameter
zur Intonation etc.) in ein Signal umgewandelt werden, das über einen
Lautsprecher hörbar ist. Zwei verschiedene Verfahren sind verbreitet:
Zum einen konkatenative Verfahren wie die Diphonsynthese (siehe hierzu
den Artikel von Caren Brinckmann in diesem Band), zum anderen die
sogenannte Formantsynthese. Bei dieser wird das Sprachsignal nicht aus
vorher aufgenommenen Signalstückchen erzeugt, sondern es wird
sozusagen »aus dem Stand heraus« berechnet.
Dabei werden verschiedene Parameter modelliert, die aus der Analyse
von Sprachschall bekannt sind. Die bekanntesten und auch wichtigsten
sind die Formanten mit deren Frequenzen, Bandbreiten und Amplituden.
Formanten sind Energiegipfel in bestimmten Frequenzbereichen, die
durch Positionen und Bewegungen der Artikulatoren, vor allem des
Zungenrückens, verändert werden und für eine andere Qualität
(Klangfarbe) hauptsächlich von Vokalen sorgen.
Andere Parameter sind beispielsweise die sogenannten
Anti-Resonatoren oder Zeros (= Energietäler in bestimmten
Frequenzbereichen), die vor allem für Nasale wichtig sind. Ein
weiterer wichtiger Parameter ist die Dauer von Lautsegmenten.
Um
koartikulatorischen Erscheinungen (gegenseitige Beeinflussung von
Lauten), Assimilationen (Anpassung eines Lautes an den benachbarten),
Reduktionen (Reduzierung bestimmter Parameter eines Lautes) und
Transitionen (Übergänge zwischen den Lauten) adäquat zu modellieren,
werden kontextsensitive Regeln eingesetzt, um die entsprechenden
Parameter für einen bestimmten Zeitabschnitt zu verändern.
Eingesetzt werden kann die Formantsynthese hervorragend für
Untersuchungen zur Sprachperzeption, da viele Parameter konstant
gehalten, andere verändert werden können. Man erhält Erkenntnisse
darüber, welche Veränderungen welcher Parameter für welches Phänomen
sprachlicher Wahrnehmung verantwortlich sind. Allerdings wird das
Resultat einer Formant-, verglichen mit einer Diphonsynthese, von
vielen Hörern als wesentlich schlechter beurteilt.
Literatur
- [Allen/Sharon/Klatt 1987]
- Allen, J. H./Sharon, M./Klatt,
D.: From Text to Speech: The MITalk System. Cambridge Studies in
Speech Science and Communication. Cambridge [etc.]: Cambridge
University Press, 1987.
- [Klatt 1987]
- Klatt, D. H.: Review
of Text-to-Speech Conversion for English. In: Journal of the
Acoustical Society of America [JASA] 82, S. 737793.
- [Traber
1995]
- Traber, C.: SVOX: The Implementation of a Text-to-Speech
System for German. Diss. ETH Zürich. Zürich: vdf Hochschulverlag,
1995.
Anhang: Aufbau eines fiktiven
Sprachsynthesesystems
Zurück zur
Übersicht der Beiträge