ziel ist, daß von einer a priori möglichen oberflächenform (einem
sog. input-kandidaten) diejenigen teilstrukturen
herausgefiltert und gezählt werden können, für welche das jeweils
betrachtete constraint »falsch« liefert (die »verstöße« eben).
weniger vorhanden sind (technisch ist dies
anders gelöst: »freischwebende«, d. h. nicht nach oben zugeordnete,
teilstrukturen gelten als nicht vorhanden; die grundmenge wird so
eingeschränkt, daß alle einheiten der tiefenstruktur mit drin
sind; und »parse(a)« muß von einheiten der kategorie a
verlangen, daß sie nach oben zugeordnet sind. vgl. abb.2).
|
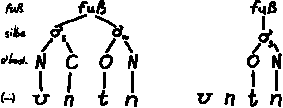 |
| Abb. 2: |
prosodische darstellung der kandidaten
![*['un.tn]](hiller_ot_untn.gif) und
und
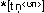 von handout 2
von handout 2
|
|---|
zur behandlung der morfologie sind evtl. noch constraints nötig,
die für die ausrichtung eines affixes (links vom wortstamm oder rechts
davon) verantwortlich sind, etc. für die übrigen constraints ist
jedoch die »tiefenstruktur« unzugänglich!
2.3 auswertung
zwei kandidaten (also elemente der grundmenge) werden
verglichen, indem die anzahlen der verstöße für jedes constraint,
ausgehend vom höchsten, verglichen werden (ein constraint ist also
jeweils bloß dann für den vergleich wichtig, wenn nach allen
höherrangigen »gleichstand« zwischen den beiden kandidaten geherrscht
hätte). der nach dieser betrachtungsweise »kleinste«, also
optimale, kandidat ist die nach dieser grammatik zulässige
form (theoretisch kann es natürlich mehrere »minimale kandidaten«
geben; dann gibt es mehrere grammatisch zulässige formen, d. h. dann
hat mer echte optionalität). zum genaueren vorgehen vgl. handout 1
(dort sind z. t. fachbegriffe aus der mathematischen logik bzw. aus
dem bereich hierarchischer merkmalsformalismen verwendet. sie sollten
in jeder entsprechenden einführungsliteratur zu finden sein).
diese darstellungsweise kann mer noch erweitern, indem mer für
bestimmte constraints einzelne verstöße noch nach ihrer »schwere«
ordnet. ein beispiel ist auf handout 2 und 3 gezeigt, wo ein verstoß
gegen das constraint *struc(nukl.) mit einem bestimmten segment in
diesem nukleus jeweils als »schlimmer« zählt, als einer mit einem
sonoreren segment.
3. morfofonologie
eine o.t.-grammatik ist im prinzip einschichtig, d.h. es
besteht (in der idealen o.t.-version) auch die morfologie nicht aus
einer zeitlichen abfolge von veränderungen, sondern findet auf einer
ebene mit der fonologie statt.
abgesehen von fill und parse wird das zusammenspiel von morfologie
und fonologie hauptsächlich über verschiedene align-constraints
geregelt. diese sind (wieder mal) parametrisch; ein verstoß ist eine
einheit einer kategorie a, die zwischen dem linken
(bzw. rechten) rand einer einheit A und dem am nächsten links
(rechts) liegenden rechten (linken) rand einer einheit B liegt
(also align(A, l/r, B, l/r, a),
vgl. abb. 3). dabei ist meist A eine morfologische kategorie
und B eine prosodische (oder sonst fonologische).
| 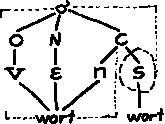 |
| Abb. 3: |
ein ALIGN(wort, R, silbe, R, X)-verstoß |
|---|
auf handout 3 ist ein beispiel vorgeführt, wie mer mit einer
solchen analyse den unterschied zwischen dt. »murren« und »turm«
(bzw. »schnorren« und »horn«, o. ä.) darstellt, die bloß wegen ihrer
verschiedenen morfologischen struktur unterschiedlich syllabifiziert
werden.
4. sprachvergleich und universalien
entstanden ist die o. t. aus der beobachtung heraus, daß offenbar am
ehesten bedingungen für eine möglichst wünschenswerte oberflächenform
in allen sprachen im prinzip gleich oder ähnlich sind. regeln eines
generativen grammatikformalismus müssen dagegen oft schon bei
kleinsten unterschieden in der sprache völlig neu formuliert werden.
in der forschung mit o. t. versucht mer also, universell die
gleiche menge von constraints anzunehmen. sprachspezifisch sind diese
constraints dann nur unterschiedlich geordnet. auf handout 4 soll an
einem beispiel anschaulich gemacht werden, wie dies dann zu jeweils
unterschiedlichen ergebnissen führt: während z. b. das deutsche eher
silben mit einer coda zuläßt als epenthesen, bleibt im japanischen dem
beispielwort bloß eine epenthese, um die optimale form zu sein.
5. wichtige eigenschaften
ursprünglich war die o. t. also durch den sprachvergleich motiviert:
erfahrungsgemäß lassen sich gemeinsamkeiten und unterschiede zwischen
sprachen viel eher über ihre anforderungen an eine »gute«
oberflächenform beschreiben, als über generative regeln. die
hauptrichtung der o. t. geht sogar noch weiter, nimmt sämtliche
constraints als universal an und variiert bloß deren gewichtung von
sprache zu sprache.
durch diese art der beschreibung fällt auch der formale unterschied
zwischen »markiertheits-tendenzen« und demjenigen weg, was bislang
durch regelableitungen beschrieben worden ist. vielmehr stellen die
»markiertheits-tendenzen« in gestalt der constraints (zusammen mit
ihrer sprachspezifischen ordnung) nun selber die grammatik dar.
eine dritte neuerung gegenüber der generativen beschreibung ist,
daß o. t.-grammatiken einschichtig (»monostratal«) sind. zwar
sind schon länger methoden bekannt, wie sich eine generative
fonologische (und morfologische) beschreibung automatisch in eine
darstellung durch (dort allerdings unverletzbare) constraints
umwandeln läßt (und diese wiederum in eine rechnerisch effiziente
darstellung; vgl. u. a. [koskenniemi 1983], [koskenniemi 1986],
[kinnunen 1986]). neu ist in der o. t. aber, daß sich die constraints
ausschließlich auf die oberflächenform beziehen. (die einzigen, die
sich doch gewissermaßen auf eine »zugrundeliegende repräsentation«
beziehen, sind die parse- und fill-constraints. diese sind aber gerade
ausschließlich dazu da, in form von constraints unter
anderen jene »tiefenstruktur« zu vertreten). damit kann mer
vielleicht prinzipiell genauso viele grammatiken ausdrücken, aber
nicht mehr so viele scheinbar sinnvolle, d. h. die im einklang mit
anderen erkenntnissen stehen.
6. ausblick
falls sich der zuletzt genannte punkt durchhalten läßt, heißt das, daß
die o. t. ein erkenntnisgewinn ist. falls nicht, läßt sich die
o. t. bloß stark abgeschwächt weiterführen (z. b. gibt es im
japanischen vokalepenthesen auch wegen eines konsonanten, der dann in
manchen fällen gar nicht an der oberfläche auftaucht; im holländischen
werden z. t. konsonanten auslautverhärtet, die an der oberfläche im
silbenansatz stehen; etc.). so oder so hat die o. t. aber genug
vorteile, daß sich eine ernsthafte fonologin damit vorerst wird
auseinandersetzen müssen.
den o.t.-formalismus auf andere gebiete der linguistik zu
übertragen ist dagegen bis jetzt kaum versucht
worden. erfolgversprechend würde dies aber auch bestenfalls in der
pragmatik aussehen.
7. literatur
7.1 zum einarbeiten in o. t.
- [mccarthy/prince 1993]
- mccarthy, john/prince, alan: prosodic morphology i: constraint
interaction and satisfaction. new brunswick nj: rutgers center for
cognitive science technical reports, 1993.
- [mccarthy/prince 1994a]
- mccarthy, john/prince, alan: generalized alignment. new brunswick
nj: rutgers center for cognitive science technical reports, 1994 (?).
- [mccarthy/prince 1994b]
- mccarthy, john/prince, alan: the emergence of the unmarked:
optimality in prosodic morphology. new brunswick nj: rutgers
optimality archive, 1994.
- [prince/smolensky 1993]
- prince, alan/smolensky, paul: optimality theory: constraint
interaction in generative grammar. new brunswick nj: rutgers center
for cognitive science technical reports, 1993.
7.2 hier im text außerdem zitiert
- [kinnunen 1986]
- kinnunen, maarit: morfologisten sääntöjen kääntäminen äärellisiksi
automaateiksi. [die übersetzung von morfologischen regeln in endliche
automaten.] diss. universität helsinki, informatische
fakultät. Helsinki: 1986.
- [koskenniemi 1983]
- koskenniemi, kimmo: two-level morphology: a general computational
model for word-form recognition and production. helsinki: univ. of
helsinki dept. of general linguistics publication no. 11, 1983.
- [koskenniemi 1986]
- koskenniemi, kimmo: compilation of automata from morphological
two-level rules. in: papers from the fifth scandinavian conference of
computational linguistics, helsinki, 11.12. 12. 1985. helsinki:
univ. of helsinki dept. of general linguistics publication no.15,
s. 143149.
Zurück zur Übersicht der Beiträge
