Quelle: [Kent/Read 1992].
Bei dem Mikrosegmentsynthese-Projekt des Phonetischen Instituts an der Universität des Saarlandes unter der Leitung von Professor W. J. Barry geht es darum, in Zusammenarbeit mit der Softwarefirma G-Data ein Sprachsynthesesystem für den Low-Cost-PC-Markt zu entwickeln, das gut verständlich ist und mit einem Speicherbedarf von 1 Megabyte für die Sprachdaten auskommt.
Grundlage oder auch Ausgangspunkt der Mikrosegmentsynthese ist die Diphonsynthese. Wie auch die Phon- oder Wortsynthese handelt es sich hierbei um eine konkatenative Methode, d.h. daß die einzelnen Segmente, die hinterher wieder zusammengesetzt werden, von einem menschlichen Sprecher stammen und in Trägerwörtern oder -sätzen aufgenommen wurden. Im Gegensatz zur Phonsynthese, bei der die synthetisierten Wörter aus den einzelnen Lauten der entsprechenden Sprache zusammengesetzt werden, nimmt man bei der Diphonsynthese Lautpaare. Die Diphone reichen dann von der Mitte (= steady state: relativ konstante spektrale Eigenschaften) des ersten Lauts bis zur Mitte des zweiten.
Wer schon einmal Phon- und Diphonsynthesesysteme hören konnte, weiß, daß die Phonsynthese im Gegensatz zur Diphonsynthese eine kaum verständliche Ausgabe liefert. Woran liegt es nun, daß die Diphonsynthese so viel bessere Ergebnisse liefert (und fast natürlich klingt)?
Während wir sprechen, sind unsere Artikulationsorgane fast ständig in Bewegung von der Zielposition eines Lauts zur Zielposition des darauffolgenden Lauts. Die spektralen Eigenschaften eines Sprachsignals (d. h. seine Klangqualität) hängen unmittelbar von der Form des Ansatzrohrs ab, die durch die Stellung der Artikulationsorgane (Zunge, Lippen, Velum und Kiefer) bestimmt wird. Sind diese also in Bewegung, so ändert sich auch das Spektrum des akustischen Sprachsignals kontinuierlich. Wenn man nun beispielsweise ein [a:] aus »baden« ausschneidet, so ist zwar der mittlere Teil des ausgeschnittenen Segments in seinen spektralen Eigenschaften relativ konstant, an beiden Enden treten allerdings mehr oder weniger starke Formantbiegungen auf.
Die Formanten eines Lauts sind diejenigen Frequenzbereiche des Anregungssignals (hervorgerufen durch die Schwingung der Stimmlippen oder durch eine enge Konstriktion im Mundraum), die abhängig von der Stellung der Artikulatoren vom Ansatzrohr verstärkt werden. Wenn sich während der Produktion eines Vokals die Artikulatoren schon auf die Zielposition des darauffolgenden Konsonanten hinbewegen, so ändern sich die Formanten und damit die perzipierte Klangqualität. Selbst wenn bei unserem ausgeschnittenen [a:] keiner der beiden benachbarten Verschlußlaute mehr im Signal vorhanden ist, so können wir doch hören, daß dem [a:] ein bilabialer Laut vorangeht und ihm ein alveolarer Laut folgt.
| |
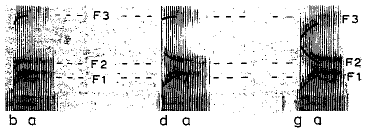
| Abb.: | Spektrogramme mit hervorgehobenen Formantübergängen für die Silben
/ba/, /da/ und /ga/. Man beachte die Unterschiede bei den F2- und
F3-Transitionen, aber die Einheitlichkeit der F1-Transition.
Quelle: [Kent/Read 1992]. |
|---|
Hängt man nun wie bei der Phonsynthese ganze Laute aneinander, die aus Trägerwörtern ausgeschnitten wurden, so ist in jedem Laut noch die spektrale Information seiner ursprünglichen Nachbarn vorhanden, unser Gehör versucht, diese zu interpretieren, und kommt zu Ergebnissen, die die Phonsynthese unverständlich werden lassen. Neben den konstanten Phasen eines Lauts sind also die Transitionen von einem Laut zum nächsten von entscheidender Bedeutung für die Perzeption. Da bei der Diphonsynthese gerade die Transitionen in der Mitte der Segmente liegen, die man aneinanderhängt, und die »Schnittstellen« in den steady states liegen, kommt man hier zu erstaunlich natürlich klingenden Ergebnissen.
Bei der Diphonsynthese stellt aber die Speicherintensität ein Problem dar. 1 MB Speicherplatz würden für höchstens 300 Diphone ausreichen (ausgehend von 22 kHz Abtastrate und 8 Bit/Sample), ein Synthesesystem für das Deutsche benötigt aber etwa 1200 Diphone. Das Prinzip der Mikrosegmentsynthese liegt daher in der »Zusammenfassung« der Diphone: Da die Form der oben erwähnten Formanttransitionen maßgeblich von der Artikulationsstelle des benachbarten Lauts abhängt, werden die kritischen Laute (vor allen Dingen die Vokale) in zwei Hälften aufgeteilt - die Mikrosegmente. Die erste Hälfte beginnt mit der Transition von der vorhergehenden Artikulationsstelle und endet im steady state, die zweite Hälfte beginnt im steady state und endet mit der Transition zur nachfolgenden Artikulationsstelle. Beispiel: Das [a:] aus [ba:d´n] wird in die Mikrosegmente lab[a] und [a]alv aufgeteilt (mit »lab« für labiale und »alv« für alveolare Artikulationsstelle). Bei der späteren Synthese durch Konkatenation der Mikrosegmente kann bei den Folgen [pa, ba, ma, fa, va] das lab[a]-Segment und bei den Folgen [at, ad, an, al, as, az] das [a]alv-Segment verwendet werden.
Bei der Erstellung unseres Mikrosegment-Synthesesystems (das den schönen Namen »Legox« trägt und wahrscheinlich ab Ende 1995 für 39. DM im Fachhandel käuflich zu erwerben sein wird) haben wir zunächst für alle deutschen Lautpaare Trägerwörter gesucht und diese von einer Sprecherzieherin alle auf der gleichen Tonhöhe sprechen lassen. Dann kam die Probierphase, in der wir herausgefunden haben, welche Mikrosegmente für welche Lautpaare eingesetzt werden können. Es stellte sich heraus, daß die Übergänge von den Lenis-Plosiven zu den Vokalen auch für Fortis-Plosive, Frikative und Nasale derselben Artikulationsstelle verwendet werden können (was umgekehrt wegen der zusätzlichen Friktion bzw. Nasalierung nicht der Fall ist). Also haben wir alle Labial-Vokal-Mikrosegmente aus [b]-Vokal-Wörtern geschnitten. Im Gegensatz zu den Vokalen kann man bei Frikativen und Sonoranten auf die Aufteilung in zwei Mikrosegmente verzichten und hier tatsächlich ganze Phone verwenden, wobei aber der linke oder der rechte phonetische Kontext von Bedeutung sein kann (z.B. ändert [S] seine Qualität je nach nachfolgendem Vokal). Der Akzentuierungsgrad eines Segments wird durch sechs verschiedene Dauerstufen variiert (von kurzunbetont bis langbetont). Schließlich haben wir noch die Regeln zur Umsetzung von der phonetischen Lautschrift eines Wortes in die entsprechende Mikrosegmentkette aufgestellt. Die Graphem-zu-Phonem-Umwandlung wird durch Lexikonzugriff abgedeckt (Wortstamm-, Affix- und Silbenlexikon). In der jetzigen Version spricht das System zwar verständlich, aber immer monoton auf derselben Tonhöhe und ohne gliedernde Pausen zwischen den einzelnen Satzteilen. Daher ist jetzt unsere nächste Aufgabe, Regeln für die Einfügung von Pausen und Enddehnung und Regeln für die Erstellung einer passenden Intonationskontur aufzustellen. Dabei können wir nur auf Informationen des Lexikons zurückgreifen (Wortartbestimmung) und daraus die Bildung von rhythmischen und intonatorischen Gruppen ableiten. Die Frequenzänderung der Mikrosegmente erfolgt dann durch Dehnen oder Stauchen des Teils eine jeden Periode, in der die Stimmlippen geöffnet sind. Damit läßt man den Teil der Periode unverändert, in dem die spektralen Eigenschaften des Lauts hauptsächlich enthalten sind, und verändert durch die Frequenzänderung die Klangqualität nur wenig. Jetzt steht uns also noch eine sehr komplexe Aufgabe bevor, deren Lösung ein Synthesesystem ergeben soll, von dem man sich auch gern eine längere Zeit etwas vorlesen lassen würde.